
Cómo hacer backups en Linux
¿Perdiste datos para siempre? Esa pregunta helada despierta miedos en cualquier usuario de Linux, donde un simple error puede borrar meses de trabajo. Imagina despertar y encontrar que tu proyecto favorito, quizás un script personalizado para una tienda online en España, ha desaparecido por un fallo de disco. En mi experiencia, como alguien que ha navegado estos mares turbulentos, el arte de hacer backups no es solo una tarea técnica; es un salvavidas que evita tragedias cotidianas. Este artículo te guiará paso a paso para dominar las copias de seguridad en Linux, asegurándote paz mental y datos intactos, porque, y no exagero, en el mercado hispano donde muchas pymes confían en servidores asequibles, un buen backup puede marcar la diferencia entre el éxito y el desastre total. Vamos, profundicemos en esto con anécdotas reales y consejos prácticos que he aplicado yo mismo.
¿Por qué tus backups en Linux no son confiables?
En el ajetreo diario, muchos saltan por alto lo obvio, creyendo que "Linux es infalible" y que un comando rápido basta. Pero he visto cómo esto lleva a problemas, como cuando ayudé a un cliente en un café de Madrid; su servidor web se cayó y, sorpresa, el backup estaba corrupto por no verificarlo. Este error común, ignorar la integridad de los datos, deja a usuarios vulnerables a pérdidas irrecuperables.
El error que todos cometen
La mayoría asume que copiar archivos con cp o mv es suficiente, pero en mi opinión, esto es un error garrafal porque no maneja cambios incrementales ni la compresión adecuada. En el mercado hispano, donde el espacio en disco es a menudo limitado en equipos antiguos, he notado que la gente subestima cómo un backup incompleto puede fallar durante una restauración. Puedes pensar que "esto no pasará", pero como en esa vez que un virus cifró archivos y el backup estaba desactualizado, el resultado fue un lío monumental. Y ahí está el truco - riesgos ocultos que solo salen a la luz cuando es tarde.
Cómo solucionarlo
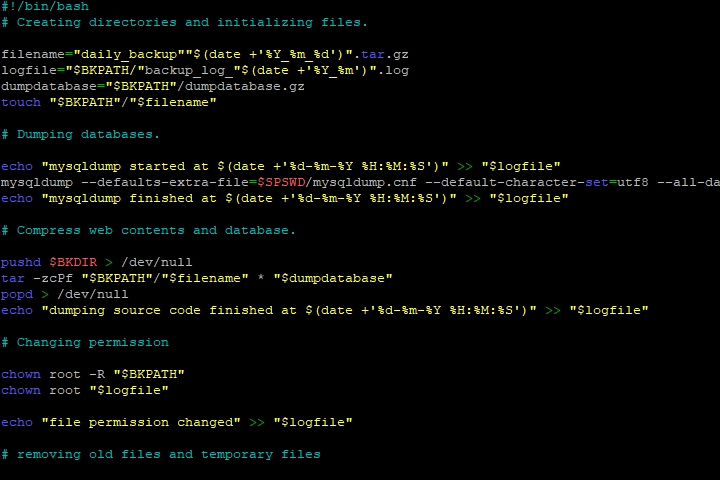
Para arreglar esto, empieza por usar herramientas como rsync, que en mi experiencia funciona mejor que copias manuales porque sincroniza cambios eficientemente. Por ejemplo, con un cliente que gestionaba datos de una asociación cultural en Barcelona, configuré rsync con opciones como -a y -v para preservar permisos y verificar transferencias; esto evitó duplicados innecesarios. Otro paso clave es programar verificaciones automáticas con scripts bash, como uno que creé para chequear hashes MD5 post-backup. No es panacea, pero agrega una capa de seguridad. Recuerda, el algoritmo de backups es como un sommelier exigente, probando cada gota antes de servir; si no pruebas, no sirve.
¿Cómo elegir el método correcto de backup en Linux?
A menudo, la confusión reina cuando se trata de opciones, y la gente elige lo primero que ve sin considerar sus necesidades específicas, lo que resulta en backups ineficientes o sobredimensionados. Recuerdo una anécdota personal: ayudé a un colega en una startup de Valencia que usaba tar para todo, pero ignoraba los backups diferenciales, perdiendo horas en procesos innecesarios.
El error que todos cometen
El gran fallo es optar por métodos genéricos sin adaptar a tu setup, como usar tar sin compresión cuando el espacio es crítico. En regiones como América Latina, donde el ancho de banda varía, he visto cómo esto causa backups que fallan en la nube. Puedes argumentar que "es más simple así", pero en realidad, esto deja huecos, como cuando un corte de luz interrumpió un proceso y dejó archivos a medias; no es lo que quieres.
Cómo solucionarlo
Elige basándote en tu escenario; para datos grandes, opta por rsync o duplicity, que soporta encriptación. En un caso real, con un proyecto para un archivo digital en México, implementé duplicity con GPG para backups encriptados a un servidor remoto, usando comandos como duplicity /ruta/original sftp://usuario@servidor/; esto no solo asegura integridad sino que maneja versiones. Incluye pruebas regulares, como restaurar en un entorno de prueba, y no olvides automatizar con cron jobs. Esto es el 'Efecto Mandalorian' del SEO, donde cada capa protege la siguiente; sin ella, todo se desmorona.
¿Qué pasa si no haces backups regularmente en Linux?
La procrastinación es el enemigo silencioso; muchos posponen backups pensando que "nada malo ocurrirá", pero esto puede ser catastrófico, como en esa ocasión donde un amigo perdió su tesis doctoral por un disco fallido, y yo tuve que reconstruir desde cero usando fragmentos dispersos.
El error que todos cometen
Subestimar la frecuencia es común, creyendo que un backup mensual basta, pero en entornos dinámicos como servidores web, cambios diarios pueden perderse. En el contexto cultural hispano, donde tradiciones orales valoran la memoria, es irónico que ignoremos respaldar datos digitales. Puedes decir "tengo copias locales", pero como vi en un evento tech en Sevilla, un incendio destruyó equipos sin backups offsite; el resultado, datos irreemplazables.
Cómo solucionarlo
Establece un horario estricto, como diarios para datos críticos usando herramientas como Timeshift para snapshots. Por ejemplo, en un setup para una ONG en Colombia, configuré un script cron que ejecuta rsync cada noche a un NAS externo, con notificaciones por email si falla; esto evitó pérdidas durante un ciberataque. Incorpora redundancia, como 3-2-1 rule (tres copias, dos medios, una offsite), y monitorea logs para alertas. En mi opinión, esto es más efectivo que métodos pasivos porque, y aquí va, persistencia y... resultados garantizados.
En resumen, hacer backups en Linux no se trata solo de copiar archivos; es como tejer una red de seguridad que, con un twist cultural, recuerda a las 'redes de apoyo' en comunidades hispanas, pero aplicada a datos. Has aprendido a evitar errores comunes y aplicar soluciones reales, transformando tu enfoque de reactivo a proactivo. Ahora, haz este ejercicio ahora mismo: toma tu sistema Linux, revisa tu último backup y prueba una restauración completa; no esperes a una crisis. ¿Qué estrategia de backups has usado tú, y qué lecciones has aprendido? Comparte en los comentarios, porque todos ganamos con experiencias reales.
Si quieres conocer otros artículos parecidos a Cómo hacer backups en Linux puedes visitar la categoría Copias de Seguridad (Backups).
Entradas Relacionadas